
Using Jsoup With Kotlin To Scrape Wiki Pages

In this article, I will explain using Jsoup library with Kotlin language. Jsoup helps us to parse and extract data from HTML documents. Depending on the use-case we can use this library to scrape various HTML pages and extract required information.
Jsoup is a Java library for working on HTML pages. This library provides API for extracting and manipulating data.
Wiki has huge number of pages dedicated to Movies and I created a small Kotlin program which scrapes these Movie pages. I will show the details and explain how I developed it in this article. My idea was to choose any Wiki page which contains list of movies and go through each movie from the list and scrape the data from that wiki page.
Here is the link of a wiki page which I worked on List of films with a 100% rating on Rotten Tomatoes. Below is the screenshot from Wiki page.
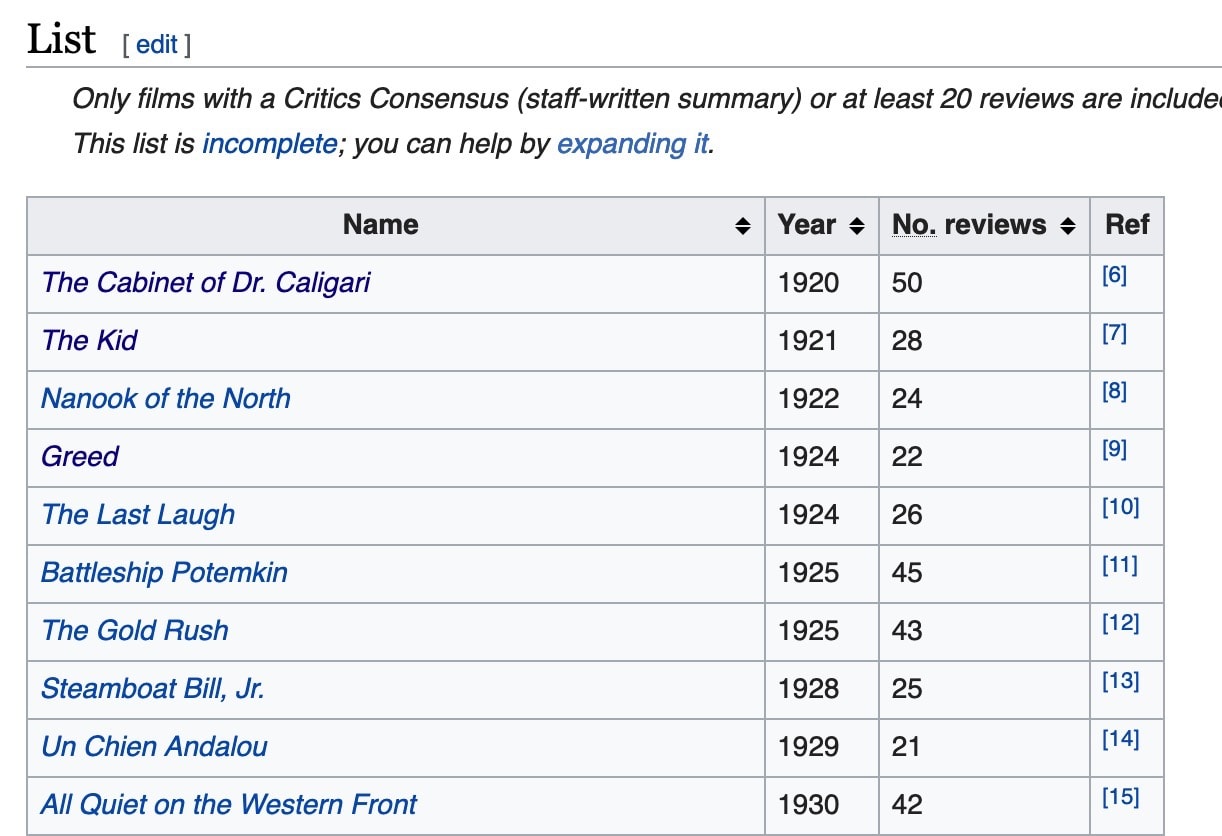
This page contains list of 100% rated movies on Rotten Tomatoes. My code will go through each row in the table and for each row it performs below tasks;
- Extracts first column from the row because it contains movie title and the URL. For example, first row in the table is The Cabinet of Dr. Caligari and its URL is https://en.wikipedia.org/wiki/The_Cabinet_of_Dr._Caligari
- For each URL, loads the page and extracts its content into a Movie instance.
Once all movie instances are created then we can insert them into a database with any ORM library, but in this article I am not going to perform any database operations.
Lets dive in to the details.
Please note that this whole project is available in github
Create Kotlin project
Execute below command to create an empty gradle Kotlin project. Once the project is created then import it into your favorite editor.
mkdir wiki-scraper
cd wiki-scraper
gradle init --type kotlin-application
Select build script DSL:
1: groovy
2: kotlin
Enter selection (default: kotlin) [1..2]
Project name (default: wiki-scraper):
Source package (default: wiki.scraper): net.thetechstackI executed this command on Gradle 5.2.1 version. You can choose to create kotlin project with any other build tool.
This command will create a new project with standard folder structure and default App.kt file.
Add Jsoup
Add below dependencies to your build.gradle
dependencies {
//..
implementation("org.jsoup:jsoup:1.11.3")
}Now we have our project with required dependencies. Let’s dive into the code.
Scrape HTML Page
First, we need to parse and extract URL’s of the movies from the table.
Extract movie URL’s
Kotlin execution starts from main() function so lets update App.kt with below code.
val wiki = "https://en.wikipedia.org"
fun main() {
val doc = Jsoup.connect("$wiki/wiki/List_of_films_with_a_100%25_rating_on_Rotten_Tomatoes").get() // <1>
doc.select(".wikitable:first-of-type tr td:first-of-type a") // <2>
.map { col -> col.attr("href") } // <3>
.parallelStream() // <4>
.map { extractMovieData(it) } // <5>
.filter { it != null }
.forEach { println(it) }
}- <1> Jsoup.connect(…) will connect to the URL and creates Connection object. Once the connection object is created then called get() on it so the page is parsed and returned as the Document object. We stored document in the doc variable.
Open https://en.wikipedia.org/wiki/List_of_films_with_a_100%25_rating_on_Rotten_Tomatoes in a browser. This page contains a table with all 100% rated movies. We need to extract URL’s of these movies.
Below screenshot shows the URL of the movie with browsers inspector window open.
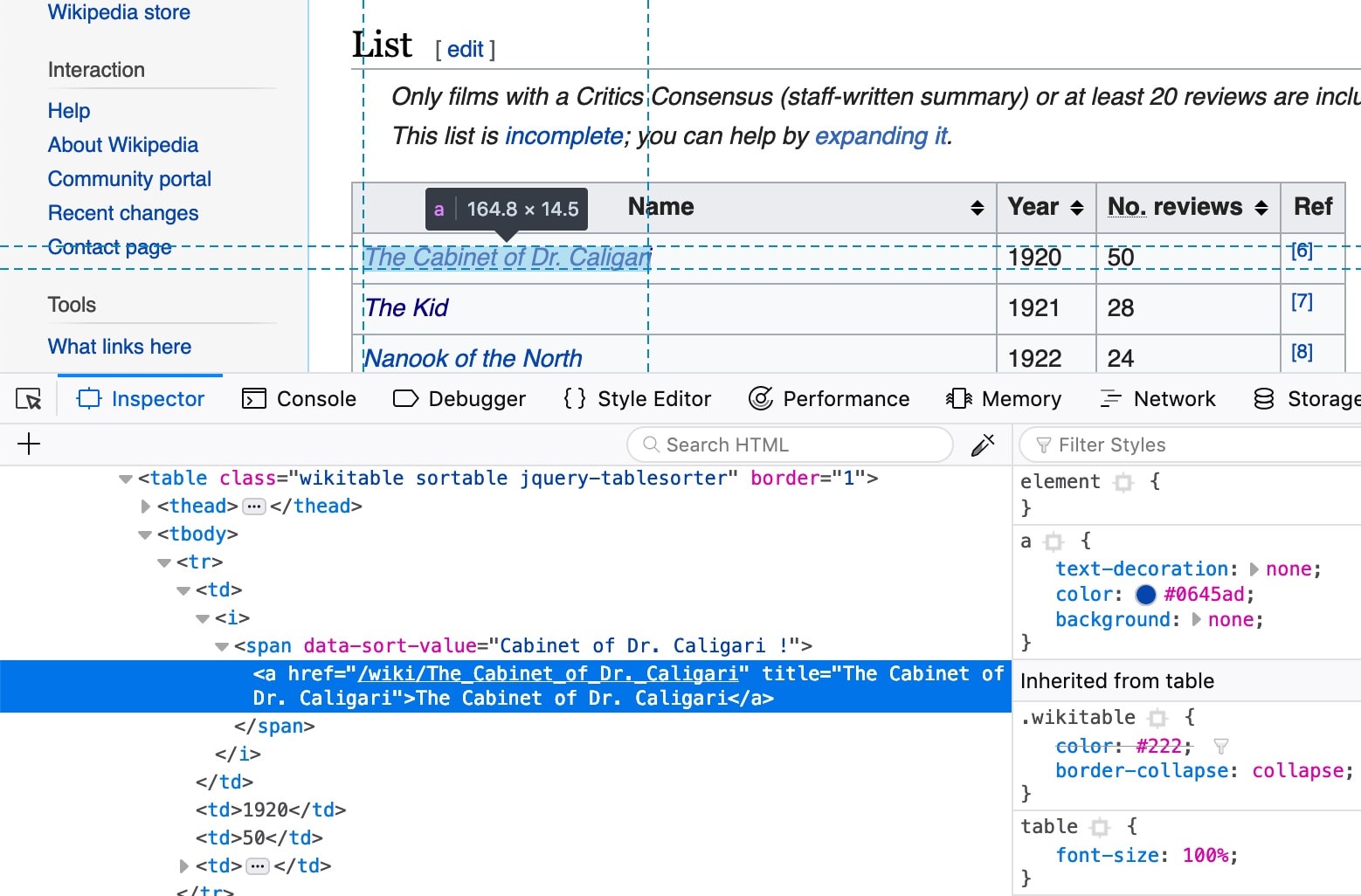
- <2> select takes a CSS query and returns all matched elements as Elements instance. Elements is a collection which extends ArrayList so we can iterate and process the elements individually. We passed .wikitable:first-of-type tr td:first-of-type a. This is a bit complex CSS query. Lets divide this into pieces to understand it;
- .wikitable:first-of-type Get first matched element which contains .wikitable class. If you inspect the page in the browser then you see the movies table contains .wikitable class.
- .wikitable:first-of-type tr Extract all rows in the table.
- .wikitable:first-of-type tr td:first-of-type but we are interested only on first column of the table because it contains the movie title with URL. So this extracts the first td.
- .wikitable:first-of-type tr td:first-of-type a With in the first column we need anchor tag because this contains the URL for the movie page.
- <3> We need href attribute because it contains the URL so using map we convert Element to String which contains the URL.
- <4> We have more than 300 movies in the table and for each movie we need to parse the movie page and extract its content so instead of doing it in sequential we can do it in parallel to speedup the process.
- <5> For each URL we call extractMovieData function. This function contains code to extract movie content.
Finally we are printing movie details to the console. At this point we will have Movie object which is returned from extractMovieData function. We can extend this example by utilizing any SQL library to save it in database. In the next section we will see the implementation of extractMovieData function.
Scrape movie page
Once the movie details are extracted we need to save the details in a object so lets create a Movie class with required fields.
class Movie {
var title: String? = ""
var directedBy: String = ""
var producedBy: String = ""
var writtenBy: String = ""
var starring: String = ""
var musicBy: String = ""
var releaseDate: String = ""
override fun toString(): String {
return "Movie(title='$title')"
}
} This class holds all the Movie related information. Once we scrape the page we are going to create the instance of this class and populate the fields.
fun extractMovieData(url: String): Movie? { // <1>
val doc: Document
try {
doc = Jsoup.connect("$wiki$url").get() // <2>
}catch (e: Exception){
return null
}
val movie = Movie() // <3>
doc.select(".infobox tr") // <4>
.forEach { ele -> // <5>
when {
ele.getElementsByTag("th")?.hasClass("summary") ?: false -> { // <6>
movie.title = ele.getElementsByTag("th")?.text()
}
else -> {
val value: String? = if (ele.getElementsByTag("li").size > 1)
ele.getElementsByTag("li")
.map(Element::text)
.filter(String::isNotEmpty)
.joinToString(", ") else
ele.getElementsByTag("td")?.first()?.text() // <7>
when (ele.getElementsByTag("th")?.first()?.text()) { // <8>
"Directed by" -> movie.directedBy = value ?: ""
"Produced by" -> movie.producedBy = value ?: ""
"Written by" -> movie.writtenBy = value ?: ""
"Starring" -> movie.starring = value ?: ""
"Music by" -> movie.musicBy = value ?: ""
"Release date" -> movie.releaseDate = value ?: ""
"title" -> movie.title = value ?: ""
}
}
}
}
return movie
}- <1> extractMovieData takes URL of the movie page
- <2> Connect and parse the HTML document but some times wiki page might not be available for the movie then Jsoup throws the Exception. Handle it and return null if page is not available.
- <3> For each movie create a new Movie instance.
- <4> Wiki assigns class .infobox to the movie table and it contains all the required information. We will select all rows from the .infobox table. Below screenshot shows the .infobox selected in browser inspector.
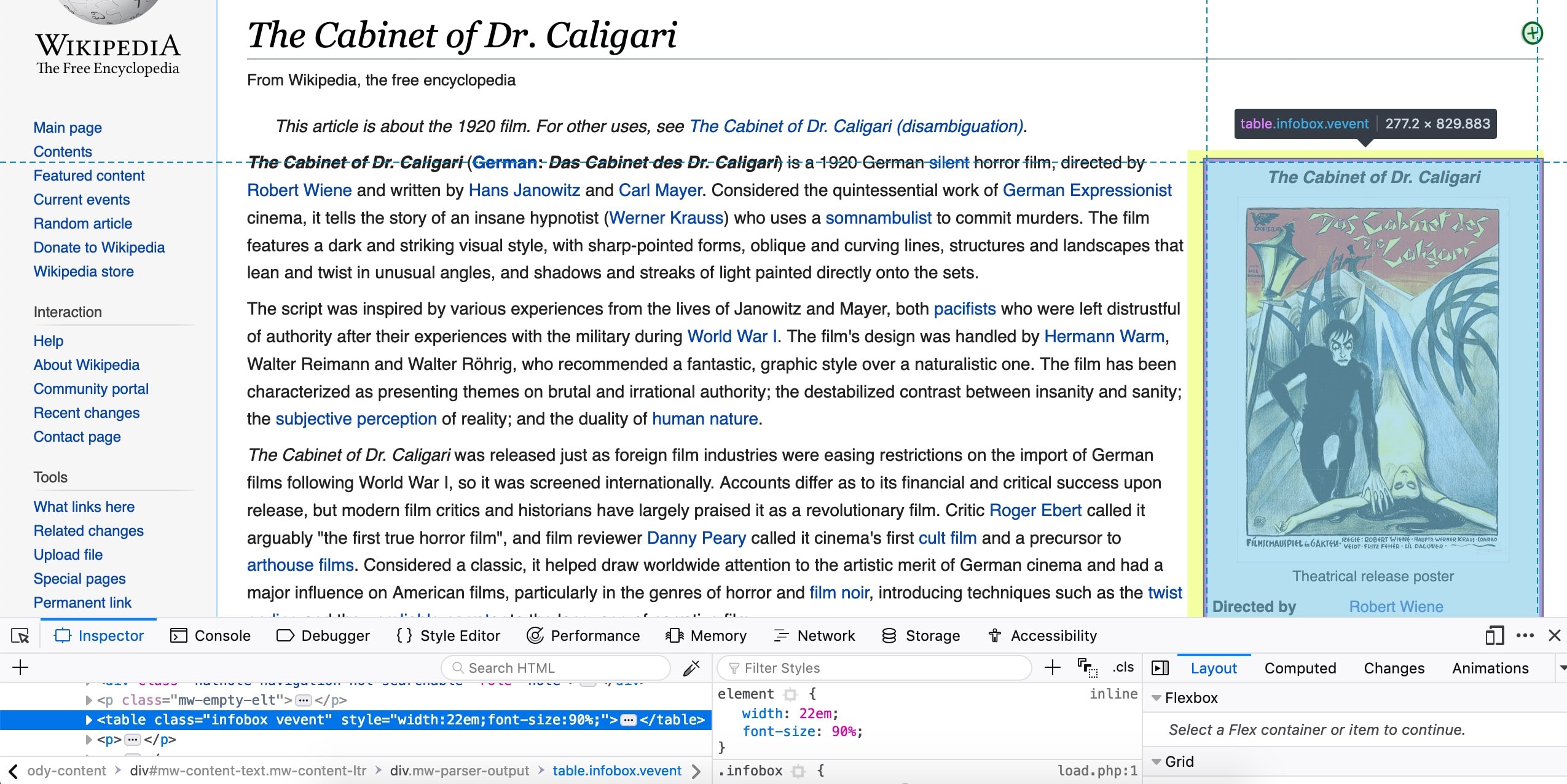
- <5> forEach is executed for each row in the table and it provides Element reference to that row. Now we can examine this row and extract needed data.
- <6> A row with .summary class will have title of the movie so we are checking if this element existing and if yes then set it to movie.title. ele.getElementsByTag(“th”)?.text() extracts the contents of the th element which contains movie title.
- <7> This is a long expression with if..else condition. Wiki can have multiple values in some rows like multiple actors in Starring in this case we need to check for multiple list items and if exists then extract text from each item and join them with comma if not then just extract the text. Final result will be assigned to value.
- <8> We have value but we need the column information so we can set this to proper field in the Movie instance. For example value in Produced by should be mapped to producedBy field in the Movie instance. First column in the row contains the header and we used when expression to check these values and for each matched column we assigned to the proper field in the movie instance.
Parallel vs Sequential processing
We can process steams in parallel by just introducing parallelStream() call. We have more than 300 rows in the table and each row is independent of each other so we can process them in parallel and it will be fast. With parallelStream() it took 7 seconds to process all movies but when I removed parallelStream() then whole process took around 17 seconds because then movies are processed in sequential.
Conclusion
We parsed list of movies in a Wiki page using Jsoup library and for each movie extracted the required data and created Movie instances.